
數據科學與計算智能:內涵、范式與機遇
|
|
中國網/中國發展門戶網訊 大數據已成為信息社會的普遍現象,是數字經濟的關鍵資源。以深度學習為代表的大數據驅動的人工智能技術在很多行業和領域獲得了成功,這類人工智能本質上源于計算能力,故可將其歸為計算智能?。與此同時,大數據是這類人工智能成功的重要因素,這類智能也被稱為數據驅動的計算智能,從這個意義上講,當前數據和智能是一體兩面的關系。雖然大數據與計算智能技術在大規模工程化應用方面取得了長足進步,但支撐技術進步的理論基礎和技術體系尚處于早期階段。當前,大數據“紅利”效應在逐漸減弱,計算智能技術的單點突破難以為大數據驅動的智能應用提供持續支撐,亟待對數據科學和計算智能的基礎問題進行深入思考,重構其理論基石,從而推動技術與工程應用持續進步和跨越式發展。
本文基于香山科學會議第?667?次學術討論會與會專家學者的集體智慧,探討并總結了?4?個方面的問題:在數據科學的內涵和外延尚缺乏嚴謹定義和學界共識的情況下,如何深入認知反映客觀世界的數據空間的共性規律?數據科學在本體論和方法論?2?個層面上需要回答的基礎問題是什么?如何理解、測試并評估現有計算智能的能力邊界?人腦、復雜社會系統、自然進化系統等自然智能,往往具備比現有計算智能更加高效的“計算思維”和更加簡潔優美的智能推演與決策能力,是否可以借鑒這些自然智能探索新的人工智能范式?在探討數據科學和計算智能的同時,有哪些值得關注的牽引性應用?新的智能范式對解決復雜的社會問題是否是一個很好的機遇?在未來的發展中,我們該如何把握時代機遇,重點關注哪些關鍵科學挑戰,優先解決哪些關鍵問題?
數據科學的內涵
基于方法論視角的數據科學內涵
關于數據科學的內涵,一種流行的看法認為數據科學就是圖靈獎得主吉姆·格雷(Jim Gray)提出的第四范式(the fourth paradigm),即在實驗觀測、理論推演、計算仿真之后的數據驅動的科學研究范式。第四范式的基本思想是把數據看成現實世界的事物、現象和行為在數字空間的映射,認為數據自然蘊含了現實世界的運行規律;進而以數據作為媒介,利用數據驅動及數據分析方法揭示物理世界現象所蘊含的科學規律。這是一種類似方法論視角來定義的數據科學的內涵,即數據驅動科學發現。
第四范式將數據科學從其前的?3?個科學研究范式中分離出來,帶來了科學發現和思維方式的革命性改變。借用美國谷歌公司研究部主任皮特·諾維格(Peter Norvig)的話來說,“所有的模型都是錯誤的,進一步說,沒有模型你也可以成功(all models are wrong, and increasingly you can succeed without them)”。海量的數據使得我們可以在不依靠模型和假設的情況下,直接通過對數據進行分析發現過去的科學研究方法發現不了的新模式、新知識甚至新規律。第四范式的一個典型研究案例是關于帕金森病的起因研究。通過對?160?萬份病歷的大數據分析,研究人員發現帕金森病的起因與人的闌尾有關。這是基于大數據統計帕金森病患病率與切除闌尾的相關性得出的結論。
第四范式通過大數據分析能夠發現數據中蘊含的大量相關關系,為科學發現提供了新視野。但是,第四范式本身無法從大量的相關關系中甄別出事物的本質規律。在發現了帕金森病和闌尾的相關性后,有些對第四范式十分執著的學者召集了更大量的帕金森病患者,以徹查他們的基因,調查他們的生活環境和生活習慣,以期從中發現一些共性;然后去找那些也有這些共性但是沒有得帕金森病的人,看他們做了什么,有什么共性;如果這種共性存在,可能就是防治帕金森病的解決方案。但是,其結論卻不盡人意。可以想象,人體的器官何止一個闌尾,且帕金森病患者的生活習慣何其繁雜,單獨靠第四范式的數據驅動方法做漫無邊際的相關性分析,不僅要消耗大量的計算資源,也難以真正預測未來的趨勢與變化。因此,從方法論來看,第四范式在揭示事物本質規律方面存在固有的局限性,數據科學需要在方法論上突破第四范式。
基于本體論視角的數據科學內涵
數據科學另外一種值得探討的內涵是基于“本體論”視角,認為數據是反映自然世界的符號化表示。既然自然世界是客觀存在并具備共性科學規律的,那么反映自然世界的數據空間也可能具有獨立于各個領域的一般性規律。因而,數據科學應該是“用科學方法來研究數據”,數據科學也應該有類似“信息論”這樣的學科基礎理論。更具體來看,當我們把世界看成是由物理世界、機器世界和人類社會組成的三元世界時,新型的“感知、計算、通信、控制”等信息技術使三元世界相互影響和融合,形成了一個平行化(孿生)的復雜數據空間。這樣的數據空間,除了映射物理世界,其本身是否具有獨特的一般性規律?如何用科學的方法來研究數據的一般性規律,揭示其內在機理?這些是數據科學更基本的問題。例如,數據科學中的一些常數規律(對稱性、黃金分割、長尾分布等)和更廣意義上的大數據非確定性、數據廣義關聯、時空演化、數據復雜性等。
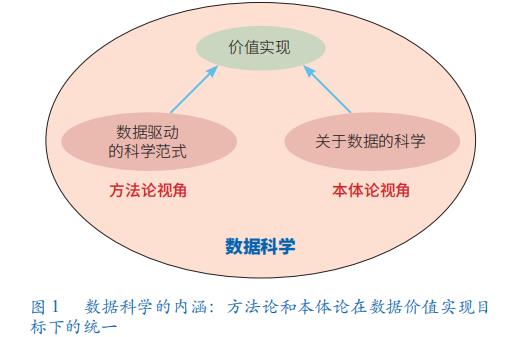
數據科學是方法論和本體論在數據價值實現目標下的統一
數據科學到底應該從哪些視角來定義其獨有的內涵與特征?一般認為,作為一門學科的定義,至少應該從其研究對象、方法論和學科目標?3?個維度去界定。數據科學的內涵應該既包括本體論內容和方法論內容,還包括其獨特的價值實現目標(圖?1)。基于這一認知,可以定義“數據科學是有關數據價值鏈實現過程的基礎理論和方法學,它運用基于分析、建模、計算和學習雜糅的方法,研究從數據到信息、從信息到知識、從知識到決策的轉換,并實現對現實世界的認知和操控”。這“三個轉換、一個實現”是數據科學的學科目標。而實現這一目標的方法論來自多個學科方法的融合,包括數學(特別是統計學)、計算機科學(特別是人工智能)、社會科學(特別是管理學)等。
數據科學與相關學科的關系
目前,關于數據科學的基本內涵和基礎問題還沒有像數學、物理學和計算機科學那樣成體系、有共識。但是,數據科學的多學科交叉特征及大數據自身的價值特性已經成為共識。我們可以借助相關學科來探討當前數據科學研究需要關注的基礎問題。
數據科學與統計學。統計學將數據作為研究對象,致力于收集、描述、分析和解釋數據,其為數據科學提供了重要基礎和工具。然而,在大數據面前,統計學也面臨著諸多問題和挑戰。例如:統計假設在復雜大數據分析中難以滿足、數據自身及分析結果的真偽難以判定、端到端的大數據推斷缺乏基礎理論支撐等。統計學針對這些問題目前基本上是束手無策的;而統計學所依賴的一些傳統強假設(如獨立同分布假設、低維假設等),也都無法適用于目前多源異質的真實數據。因此,數據科學雖然在研究對象上和統計學是相同的,但在研究問題的范疇上卻是超越統計學的。譬如:數據科學該如何深入認識數據固有的共性規律?是否能建立一套數據復雜性理論體系?數據規模、數據質量和數據價值有什么定量關系?如何刻畫大數據所表現出來的多層面的非確定性特征?
數據科學與網絡科學。數據科學的發展可以借鑒網絡科學的發展歷程,以類似的方法尋找研究對象的共性規律。網絡科學發現了物理世界中廣泛存在的網絡所呈現出的共性規律(如冪率分布、小世界現象等),從而促進了其從圖論和隨機圖論中分離出來獨立發展,實現了其研究對象從作為數學工具的圖到作為物理對象的網絡的轉變。那么在數據科學中,數據的共性規律是什么?在現實世界中是否有完全不同的兩個數據集之間存在某種共性?一方面,一下子找到所有領域的共性規律可能是不現實的,因而可以先從幾個關鍵領域出發,尋找部分領域的共性規律;另一方面,尋找數據的共性規律需要能夠問出合適的基礎性問題,類似網絡科學中關于度分布、聚集系數、網絡直徑、網絡脆弱性、網絡適航性等方面的問題。目前,尚不明確各個領域的數據是否存在統一的規律。因此,數據科學還需要在應用領域進行一定時間的探索,從領域知識中汲取養分,并逐步發現規律、尋找共性。
數據科學與計算機科學。數據科學的起源與發展離不開計算機科學,但這兩個學科由于研究對象和研究方法的不同,未來也許會平行發展。簡單而言,從研究對象的角度來說,計算機科學是關于算法的科學,而數據科學是關于數據的科學。從計算機科學到數據科學,研究手段從傳統計算機領域的算法復雜性分析,轉變為對數據的復雜性和非確定性等特性進行分析研究。如何對非確定邊界的數據,在有限時間空間下進行計算?數據復雜性、模型復雜性與模型性能之間是什么關系?解決某個問題所需要的大數據的量的邊界如何確定?是否能發展一套理論,為基于大數據的計算模型提供其能力上、下界的保證?這些都是數據科學獨立于計算機科學之外所需要解決的問題。
數據科學目前尚處于發展的早期階段,其研究方法也應該與傳統科學有所區分。數據科學,正處于“無知”到“科學”的中間狀態。它目前還沒有形成一門完整的學科——信息是不完備的,環境也是非確定的。因此,不能完全按照傳統學科來思考和要求數據科學;而應該在這樣不完備、非確定的環境下,重新思考和定義數據科學及數據科學亟待關注的基礎問題。
計算智能的發展與新型智能范式的探索
計算智能的發展
人工智能(AI)概念在1956年由麥卡錫等學者提出,其發展幾經浮沉。基于對智能產生機制的不同理解,人工智能發展至今學派眾多,且相互借鑒,形成了一系列代表性成果。無論是早期符號計算(以數理邏輯為基礎)、進化計算、支持向量機、貝葉斯網絡,還是當前在工業界獲得巨大成功的基于多層神經網絡的深度學習方法,從模型的本質上來看都是建立在圖靈機的基礎上,基本都符合邱奇-圖靈論題(Church-Turing thesis),即“任何在算法上可計算的問題同樣可由圖靈機計算”。換句話說,現有的人工智能模型本質上都是與圖靈計算模型等價的,故可歸為計算智能。計算智能一般以計算機為中心,以算法理論為基礎,充分利用現代計算機的計算特性,給出了解決實際問題的形式化模型和算法。
近?10?多年以來,大數據的使用、算力的提升和深度模型的發展,為計算智能帶來了新的契機。大數據、大算力、大模型三者結合,極大地推動了計算智能的工業化應用。例如,計算智能在以圍棋為代表的人機對弈、機器翻譯、人臉識別、語音識別、人機對話、自動駕駛等應用中均取得了巨大的成功。值得注意的是,大數據在給計算智能帶來發展的同時,其復雜性和非確定性也給計算智能帶來了非常大的挑戰。現有的計算智能在面臨大數據環境下的復雜問題和復雜系統時,依然很難給出滿意的答案。我們需要探索當前計算智能的能力邊界問題,從理論上探尋這類智能所能解決的問題類型和能力邊界。譬如,通過建立深度學習和統計力學的關系,回答深度學習的相關基礎問題:表達能力方面,模型做深為什么是必要的,到底深度為多少層是合理的?模型學習方面,崎嶇的目標函數如何高效優化? 泛化能力方面,如何實現計算智能技術從專用到通用的轉變?如何實現模型的跨領域、跨任務、跨模態的泛化?
上述一系列基礎問題將進一步成為計算智能未來發展的關鍵“瓶頸”。其原因是,當前的計算智能是大數據工程化驅動的,其能力的提升主要依賴于數據規模的增加和計算速度的增長。如果缺乏數據科學化理論的支撐,大數據驅動的計算智能難以形成從量變到質變的提升。那么另一種思路是,我們也許可以考慮發展與當前計算智能不一樣的智能范式,以便更加簡潔高效地解決更復雜、更普適的現實問題。
新型智能范式的探索
事實上,自然界中存在大量具備智能的自然系統。這些自然系統比現有人工智能系統具備更加簡潔、高效的邏輯推理和自我學習能力,如腦神經系統、社會系統、自然生態系統等。那么,自然系統的智能模型是什么?我們能否借鑒自然系統中的智能行為,將其形式化為可計算的智能范式?實際上,已有?4?類智能范式在此方面做出了一些初步的探索。
腦啟發計算
人類的大腦皮層具有?140?億—160?億個神經元,且每個神經元會連接?1?000—10?000?個其他神經元,借此人類發展出了比其他物種更高級的智慧。腦啟發計算(brain-inspired computing)正是借鑒了人腦存儲、處理信息的基本原理所發展出來的一種新型計算技術。與傳統圖靈計算機的計算模式相比,腦啟發計算是通過增加空間復雜度來保留計算單元之間的結構相關性,從而構造基于神經形態工程的高速、新型計算架構。腦啟發計算的目標是構造一套非“馮?·?諾依曼”架構、可實時處理復雜非結構化信息、超低功耗的高速新型計算架構。腦啟發計算的發展,也許能為數據科學提供新的計算架構和高性能的計算能力,支撐通用人工智能的發展。目前,腦啟發計算仍處于起步階段,我們需要進一步思考如何在不完全了解人腦機制的情況下發展腦啟發計算模式,以及如何基于這種腦啟發計算為科學研究提供新思路和新范式。
演化智能
學習和演化是生物適應環境的基本方式。現有的計算智能基本都擁有從數據中學習的能力,但對智能模型的演化能力缺乏關注。例如,人腦是經過數百萬年的演化逐步形成的。從這個角度來講,現有的智能模型在依靠人類設計之外,是否也能通過演化過程去自動發現最佳的模型結構?傳統的遺傳算法是一種基礎的演化計算模型;而從演化計算到演化智能,以及實現模型自動演化的智能范式,還有很長的路要走。未來,交互驅動的強化學習、開放環境下的人工智能是值得探索的方向。
復雜系統模擬
自然界存在大量的復雜系統,如人類社會系統、自然生態系統、人體免疫系統等。從控制和計算的角度來看,模型化的復雜系統是“由大量相互作用、相互依賴的單元構成的一個整體系統;一般在沒有中央控制情況下,這個整體系統可通過簡單的運作規則實現復雜的信息處理,進而產生復雜的集體行為,并能通過學習和進化產生自生長和自適應能力”。是否可以通過模擬復雜系統的組成特點和交互方式來構造新型智能范式?如何通過大量簡單智能體之間的交互作用,產生可預期的、具有高度復雜性的群體智能?這樣的智能范式也許會從根本上改變傳統的單智能體的智能上限。
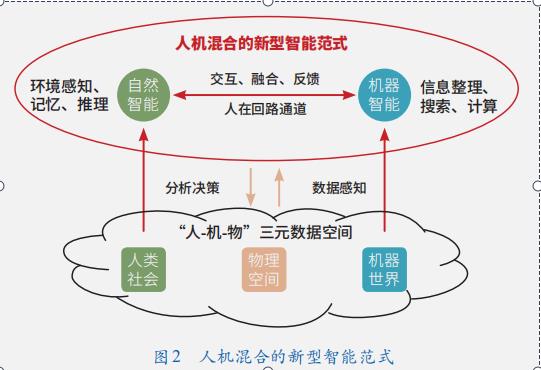
人機混合智能
隨著互聯網、物聯網及新一代通信技術的發展,萬物泛在互聯成為現實。未來,大量物理設備、無人系統、人腦,通過泛在網絡實現“上線”和“互聯”。在這樣的環境下,人在回路的人機混合智能具備了基本的物理條件。目前,人工智能技術所具備的感知、認知能力,基本上是模型與數據結合,并以機器為中心所形成的計算智能,故也稱為機器智能。這種機器智能在存儲、搜索、感知、確定性問題求解等方面性能表現優越,但在高級認知和復雜問題決策方面與人類智能相差很遠。雖然腦啟發計算取得了一些進展,但在可預期的未來,機器智能很難完全模仿和構造出人類智能或其他自然智能。換一個思路,如果將人的智能引入到機器智能的系統回路中,將充分融合人類智能和機器智能的優勢,從而形成更高級的智能水平。在未來較長的一段時間內,這種人機混合智能也許是一些復雜問題求解的有效途徑。
那么,在基于機器的計算智能基礎上,人作為具備智能的自然系統,如何參與到機器智能的系統回路中是一個關鍵問題。人機混合智能需要重點解決思維融合或決策融合的問題。具體而言,傳統的人機接口往往是單向的;在人機互聯情況下,人腦如何參與到機器智能的系統回路當中?如何同時讓人理解機器思維和讓機器理解人的思維,從而實現思維的無縫互動?目前,一些探索和挖掘思維潛力的工具,如思維導圖、思維地圖、概念圖等,其理論基礎與形式化模型并不清晰。一些新型的腦機接口技術進展迅速,但缺乏對人腦在直覺、意識、情感和決策方面的機理認知。也許,從技術上構建有效的人在回路智能通道,是當前人機混合智能亟待解決的關鍵問題之一(圖?2)。
小結
上述?4?類智能范式的研究,在現有圖靈等價的計算智能基礎上,或多或少地引入了人類智能或自然系統智能的部分機制,從而為未來智能系統的發展注入新的活力。但是迄今為止,這些智能范式在可形式化、可計算、可構造等方面還存在諸多基礎性問題挑戰。如果這些模式是未來新型智能范式,那么它們是否還是圖靈等價的?這些問題值得我們從本源上進行探討。數據是人類社會、物理世界和機器世界之間的橋梁,同時數據也是人類社會和物理世界的符號化映射。因而,從數據入手是探索和實現上述新型智能范式的基本途徑。數據科學基礎理論,不僅對當前數據驅動的計算智能起到提質增效的作用,也將為未來新型智能范式研究提供理論支撐。
引領數據科學與計算智能研究的應用
作為一門實踐性強的學科,數據科學的發展離不開實際需求牽引與技術應用驅動。隨著感知、計算、通信、控制等技術的發展及綜合集成應用,“人-機-物”三元世界高度融合,在線形成了一個網絡化的大數據系統,其內部包含了互聯網、物聯網連接而成的各類數據。這是一個高度復雜、強不確定性、持續動態演化的復雜系統,是“系統的系統”。它既是智慧城市、智能制造、健康醫療等各個領域應用的空間載體,也為國家安全、社會治理、數字經濟等領域的科學化、智能化發展提供了重要的數據資源供給。前文已提及,這個現實存在的大數據系統,除了具備高度復雜性、強不確定性等特性,人在回路也是其顯著特征。針對這一現實系統的研究與應用,將有可能為數據科學的理論與技術發展帶來機遇。針對這一復雜系統的典型場景展開研究,不僅有利于揭示數據的基本規律,也有可能因此而牽引未來新型智能范式的研究。其典型的應用場景有如下?4?種。
基于非確定數據的社會認知。在社會系統中,我們搜集到的數據通常與真實的情況存在一定的偏差,大量的虛假內容、非確定性內容混雜在這些數據當中。如何能基于這樣不完備的、非確定的大數據進行社會認知是一個非常有挑戰的問題。社會認知具體包括真假判定、社會心理計算、輿情判定與導向等。而面向非確定數據的社會認知,其中一大關鍵在于如何對大量復雜的非確定數據進行假設建模,如何建立復雜社會系統中個人行為與群體社會認知之間的關聯。演化智能、復雜系統仿真與模擬也許是解決這一問題的突破口。
基于開放環境的群智決策。互聯網極大地方便了信息、知識和智慧的互聯互通。在互聯網中,已經有許多復雜問題可以通過群智決策的方式加以有效解決,如眾包計算、人本計算等。那么,一方面,未來我們該如何設計或改進群智決策中的內部個體交互、融合與反饋方式,以人工構造的群體智能方式進一步提升互聯網群智決策的智能上限?另一方面,從計算機的視角來看,該如何利用或者模擬這種人類的群智決策方式,來解決一些復雜的決策問題?考慮到智能系統的演化及復雜系統的仿真與模擬,對單個智能體及智能體之間復雜交互進行建模,也許是未來復雜問題求解的一個可能方向。
人機融合的智慧醫療。智慧醫療是醫學、計算機科學、公共衛生學等學科相互交叉的新興領域。隨著信息技術的普及發展,醫療領域產生了大量的數據(如電子病歷、PB?級基因數據等),也催生了諸多與智慧醫療相關的應用需求。如何根據患者的電子病歷及臨床影像等數據對疾病診斷提供輔助決策支持?如何根據人類的基因數據,提前進行疾病的預測,為疾病的早期發現、新生兒的先天缺陷預測提供幫助?需要注意的是,智慧醫療需要強大的可靠性,但目前的人工智能還難以替代醫生。一種比較好的提高思路是,考慮人(醫生)在回路的新型智能范式;通過這樣人機混合的方式,使得機器的智能與人的智能相輔相成,使醫療從傳統的“個體經驗決策”轉向“智能輔助決策”的新模式,進而為醫療系統的革新帶來新的可能。
重大公共安全問題與社會治理。重大公共安全問題指對社會和公民所需的穩定環境有嚴重影響的重大問題。公共安全問題涉及多方復雜因素,包括人類社會、自然環境、突發事件等,是典型的人在回路的復雜應用問題,急需應用大數據技術手段進行預測、預警和防控。以新冠肺炎疫情為例,大數據分析技術手段和人機混合智能,為疫情走勢預測、傳播鏈排查、謠言傳播溯源和意圖研判等人在回路的復雜問題提供了有力幫助,支撐疫情精準防控。
數據科學與計算智能的關鍵問題
數據科學的發展,將幫助我們厘清數據科學的理論邊界,為計算智能的持續發展提供新的可能與機遇;與此同時,計算智能的發展與新型智能范式的興起,也將為大數據在各行業和各領域的應用提供新的契機。在本節,我們從數據科學的基本內涵與邊界、新型智能范式與智能能力測試、數據評價體系與共享利用?3?個方面出發,基于香山科學會議第?667?次學術討論會與會專家的討論,提煉形成數據科學與計算智能領域的七大關鍵問題,以期得到相關領域研究者的共同關注,從而把握時代的機遇,推動數據科學與計算智能的持續發展。
大數據中的相關關系與因果關系
因果關系指一個變量的發生會導致另一個變量的發生。而相關關系則指一個變量發生變化時,另一個變量也會規律性地發生變化。一般情況下,因果關系往往也是相關關系,而相關關系并不一定是因果關系。大數據的存在,使得人們可以廣泛尋求相關關系,Mayer-Sch?nberger甚至在其書中說道,“大數據時代最大的轉變就是放棄對因果關系的渴求,而取而代之關注相關關系”。相關關系確實能在商業和實際應用中帶來巨大的成功,但這種成功從科學角度尚需謹慎看待。從科學研究的角度來看,相關關系研究是可以替代因果分析的科學新發展,還是因果分析的補充?從實際應用看,從數據中挖掘出的相關關系能否看作是一種近似因果關系幫助人們進行預測或決策?對此,不同的學者有不同甚至相反的看法。
建議未來重點研究方向:相關關系能夠逼近因果關系的程度,相關關系和因果關系的邊界,是否可以利用反事實推斷從相關關系中推斷出因果關系,以及如何保證大數據分析的結論可信等問題。
數據科學的復雜性問題
在計算機科學中,算法的計算復雜性是一個基本問題,包括時間復雜性和空間復雜性。而數據科學除了對計算復雜性的研究外,還需要探索數據自身的復雜性及模型復雜性。數據科學不能一味地靠增加數據量或者模型的參數規模來提升其性能。給定一個具體問題,到底需要多大規模的數據或多復雜的模型才能獲得有效解?一個復雜模型判定能力的提升到底有沒有盡頭或界限?數據規模和模型復雜度之間是什么關系?這些問題在大數據工程化應用中也許可以有經驗性的判定,但是在數據科學研究中需要弄清楚其基本內涵和規律。
建議未來重點研究方向:從數據科學理論出發,給出數據復雜性、模型復雜性和模型性能之間的關系(上下界或漸進理論),為大數據的科學化研究和高效率應用奠定重要基礎;當然,要對所有領域給出一個共同的數據科學基礎理論,可能比較困難,但可以考慮先從某些重要領域或典型問題出發進行探索。
有限時空約束下的無限數據計算
在很多場景中,解決問題所需要的數據可能是大量流動的,甚至是無限的——無法確定其邊界。例如,真實的自動駕駛技術需要在任意環境、道路上都確保其有效性,理想情況下我們需要通過搜集大量的數據來不斷訓練自動駕駛模型,促使自動駕駛水平的提升;但問題在于,在實際操作中我們無法在有限時空資源下搜集、處理所有的數據。現有的自動駕駛技術,也基本都是在有限的實驗室環境下或者固定的道路上進行學習訓練,以期能夠實現在任意環境和非確定道路上的自動駕駛。
建議未來重點研究方向:面向上述邊界不確定的數據,到底多大的數據量對問題而言是足夠的,以及什么樣的數據采樣機制才能保證逼近數據整體分布;或者說,該如何在有限時空資源限制下來處理邊界不確定的數據。
強不確定性復雜系統環境下的新型智能范式
大數據空間融合了“人-機-物”三元世界,其交互方式、運行方式極其復雜。復雜系統中跨域高維稀疏的大數據具有很強的時空分布不確定性和價值規律不確定性。在這樣一個強不確定性的復雜環境下,能否形成形式化、可計算的新型智能范式?如果存在這樣的智能范式,是否還需要依靠大規模數據驅動?現有的腦啟發計算、演化智能、復雜系統模擬等主要還是依賴計算機的計算能力,未來還需要進一步探索能夠突破計算機計算能力邊界的智能范式。人在回路的人機混合智能是一個可能的發展方向,其目標是打通人類智能與機器智能的融合通道,通過有機融合方式實現人機混合智能。
建議未來重點研究方向:人機混合的智能通道構建及其方式(近幾年發展迅速的腦機接口技術、思維融合范式等);探索這類新型智能范式的主要特征是什么,是否圖靈計算等價,是對當前計算智能的改良還是顛覆,以及數據科學在其中發揮什么樣的作用等。這些開放性問題研究將為數據科學和計算智能帶來新的視野和機會。
圖靈測試以外的通用人工智能測試
圖靈測試是早期普遍被接受的人工智能測試準則,主要通過測試者(人)與被測試者(機器)在隔離情況下的問答來測試機器的智能。這是一種非常巧妙的思想實驗,但并非工程實驗。圖靈測試的?3?個開放特點——問題開放、測試者開放、語言開放,導致真正可重復的圖靈測試很難實現。而在一般的計算智能設計中,一個重要準則就是需要可重復且有效的評價方式。
建議未來重點研究方向:探尋圖靈測試之外更加科學有效的通用人工智能測試方法,以及探索以人作為標準答案和參照系之外的可重復且有效的智能評價標準。
領域無關的數據分類體系與評價指標
數據科學研究中的數據常常來自各個不同的領域,領域之間的數據類型、數據完整性、數據規律等具有非常大的差異性。我們不能只針對某個特定領域的數據來談論數據科學,而應該對所有領域的數據建立一套共同的話語體系和統一的度量標準。換句話說,需要對不同領域的大數據,進行領域無關的科學分類,構建跨領域、可泛化的數據評價指標和體系。
建議未來重點研究方向:可以從數據質量、多樣性、復雜性、不確定性或價值密度等多個維度出發,定義數據的統一評價指標。這樣的評價指標可以使不同領域的研究者對數據擁有共同話語體系,有利于以數據作為研究對象開展持續的科學化研究。
可信任的數據共享與流通
大數據是數據科學的研究基礎和研究對象,數據科學的發展離不開良性的數據治理和大數據基礎環境建設。其中一大挑戰問題是可信任的數據共享與流通。數據不同于傳統商品,可能會存在無限復制和無限使用的問題,因而造成數據流通價值失效。
建議未來重點研究方向:如何用技術手段來確保數據共享和流通的有效與安全,其中數據供給和數據使用是?2?個關鍵環節。在數據供給方面,可以考慮數據的有限供給,通過技術的手段對數據進行限量發行。例如,通過對使用數據的工具增加保護機制,實現數據的有償服務。也可以利用區塊鏈等技術,保證數據的單方持有。在數據使用方面,需要考慮數據的有界使用,保證數據的使用不涉及用戶隱私等問題。具體來說,可以利用密碼學、聯邦學習等手段,在保證隱私的前提下加密數據的傳輸,通過確立數據類型或關系而非獲得數據本身作為數據使用的主要方式。數據的共享和流通是數據開放研究的基礎,期待未來有更多的人關注數據開放的技術手段研究。
未來展望:開啟“第五范式”科學研究
在過去十幾年間,隨著可獲得和可使用的大數據持續增長,第四范式作為一種新的科學研究范式,受到科學家越來越多的關注;同時,也暴露出了很多不足。譬如:數據不確定性問題、數據復雜性問題、數據的維數爆炸問題、數據的尺度邊界問題等。目前,網絡科學、腦科學、社會科學等領域面臨的重大問題都是極其復雜且動態變化的難題,采用經典物理一樣的簡單實驗(第一范式)、基于公理和假說的理論推演(第二范式)、基于模型的計算機模擬(第三范式)和數據驅動的相關性分析(第四范式)都無法解決。為此,科學家開始尋求更接近數據和智能本質、更有效認識復雜性和不確定性的新科學研究范式。目前,這類新的科學探索方法論尚未形成定論,大體上看,這類新的科學研究范式是以智能為研究目標的浸入式具身研究,我們暫時稱之為“第五范式”。基于數據科學本體論認識,我們猜測“第五范式”和第四范式一樣都會以數據為對象,不同的是“第五范式”更側重于人、機器及數據之間交互,強調人的決策機制與數據分析的融合,體現了數據和智能的有機結合;“第五范式”強調從本體論的角度看待數據,認為數據本身蘊含自然智能的規律,也是新型智能的載體和產物,期望在數據驅動智能的同時突破現有計算智能的能力邊界,借助自然智能構造新型智能范式。
目前,針對“第五范式”的探索剛剛起步,從方法論上還歸納不出它的基本特征;但可以肯定,它的一個重要特征是“融合”,既要融合前四種范式,又要融合統計學、網絡科學、腦科學等前沿研究中涌現的新方法。第三范式和第四范式都用到計算機:第三范式是“人腦+計算機”,人腦是主角;第四范式是“計算機+人腦”,計算機是主角。第五范式既強調人腦與計算機的“有機融合”,也可能更進一步從社會系統和人腦系統借鑒其中的計算與決策機制,從而更重視人和社會在科學研究回路中的形式化建模與計算融合。
數據科學和計算智能的發展催生“第五范式”;“第五范式”發展離不開對數據科學內涵的豐富和計算智能能力邊界的突破。從研究對象看,“第五范式”是科學研究從對物理世界、人類社會的研究拓展到“人-機-物”融合的三元空間;從研究目標上看,“第五范式”不僅僅是傳統的科學發現,更是對智能系統的探索和實現;從研究方法上看,“第五范式”強調人在回路的浸入式具身研究。目前,還難以給出“第五范式”的清晰界定,也許再過?10—20?年,“第五范式”的特征就明朗了,可能逐步成為科學研究的主流范式之一。(作者:程學旗、沈華偉、李國杰,中國科學院計算技術研究所; 梅宏,北京大學;趙偉,阿聯酋沙迦美國大學;華云生,香港中文大學;《中國科學院院刊》供稿)