

人工智能驅動的生命科學研究新范式
2024-02-07 14:25
來源:中國網·中國發展門戶網




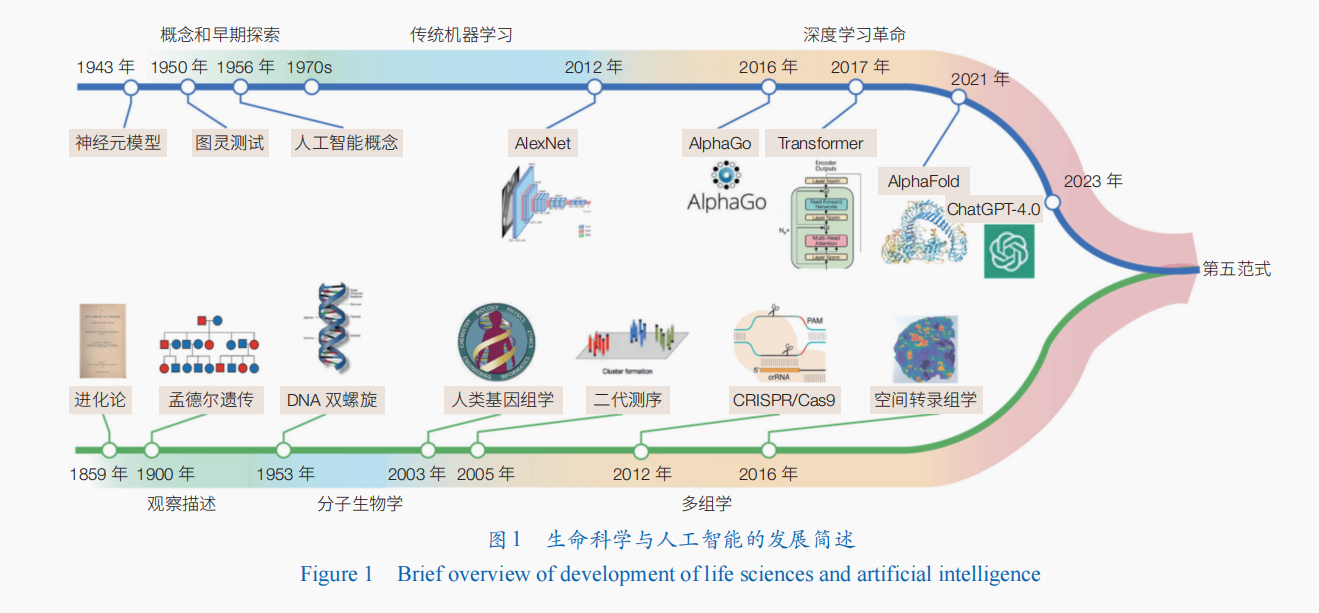
中國網/中國發展門戶網訊 2007年,圖靈獎得主吉姆·格雷(Jim Gray)提出了科學研究的四類范式,這些范式基本上被科學界廣泛認可。第一范式是實驗(經驗)科學,主要通過實驗或經驗來描述自然現象并總結規律;第二范式是理論科學,科學家通過數學模型進行歸納總結形成科學理論;第三范式是計算科學,利用計算機對科學實驗進行模擬仿真;第四范式是數據科學,利用儀器收集或仿真計算產生的大量數據進行分析與知識提取。科學研究的范式變革體現了人類對宇宙探索的深度、廣度、方式和效率的演進。
生命科學的發展經歷了多個階段,其研究范式的演進也有其獨特的學科屬性。在生命科學早期發展階段,生物學家主要通過觀察不同生物體的形態和行為模式來探索生物存在的一般形式和演化的共同規律,這一階段的代表是達爾文,通過全球考察積累了大量物種的表象描述資料,并以此提出了進化論。從20世紀中葉開始,以DNA雙螺旋結構的揭示為標志,生命科學研究進入了分子生物學時代,生物學家開始在更深層次水平研究生命的基本組成和運作規律。在這一階段,生物學家仍主要通過對生物現象的觀察和實驗來總結規律與知識。隨著生命科學的進一步發展和新型生物技術的快速涌現,科學家可以對生命科學在不同層級和不同分辨率下進行更為廣泛的探索,這也使得生命科學領域的數據呈現爆發性增長。通過高通量、多維度組學數據分析與實驗科學結合的方式對生物過程進行更加精細的描述和解析,成為現代生命科學研究的常態。
然而,生命系統具有多層面的復雜性,涵蓋了從分子、細胞到個體不同層次,以及個體間的種群關系、機體與環境的互作關系,展現出多層級、高維度、高度互聯、動態調控的特點。現有的實驗科學研究范式在面對如此復雜的生命系統時,往往只能從特定尺度對有限數量的樣本進行觀察描述和研究,難以全面理解生物網絡的運作機制;并且高度依賴人的經驗和先驗知識對特定生物關系進行探索,難以從大規模、多樣性、高維度數據中高效提取隱匿的關聯和機制。面對生命現象中復雜的非線性關系和難以預測的特征,人工智能(AI)技術展現出強大的能力,并且已經在蛋白質結構預測、基因調控網絡模擬解析方面表現出顛覆性的應用潛力,將生命科學研究由實驗科學為主的第一范式推向以人工智能驅動的生命科學研究新范式——第五范式(圖1)。
本文將從AI驅動的生命科學研究典型范例、生命科學研究新范式的內涵和關鍵要素、新范式賦能的生命科學研究前沿及我國面臨的挑戰3個方面進行系統論述。
人工智能驅動的生命科學研究典型范例
生命是一個多層次、多尺度、動態互聯、相互影響的復雜系統。在面對生命現象的極端復雜性、多尺度跨越和時空動態變化時,傳統的生命科學研究范式往往只能從局部入手,通過實驗驗證或有限層次的組學數據分析建立有限生物分子和表型的關聯關系。然而,即使花費巨大成本,也通常只能發現特定情境下的單一線性關聯機制,與生命活動的非線性屬性在復雜度上存在顯著差異,難以全面理解整個網絡的運作機制。
AI技術,尤其是深度學習和預訓練大模型等技術,以其優越的模式識別和特征提取能力,能夠在龐大的參數堆疊情況下超越人類理性推理能力,從數據中更好地理解復雜生物系統中的規律。現代生物技術的不斷發展,使生命科學領域的數據呈現跨越式增長,在過去全球范圍生命科學研究中,人類已經積累了大量基于實驗描述和驗證的數據,為AI破解生命科學底層規律創造了基礎]。當擁有充足且高質量的數據和適配于生命科學的算法時,AI模型就能夠在多層次的海量數據中以“低維”數據預測“高維”信息及規律,實現從基因序列和表達等低維數據到細胞、機體等高維復雜生物過程規律揭示的跨越,解析復雜的非線性關系,如生物大分子結構生成規律、基因表達調控機制,甚至個體發育、衰老等多因素交叉的復雜生物系統中的底層規律。在此發展趨勢下,近年來生命科學領域涌現出了蛋白質結構解析、基因調控規律解析等一批AI驅動生命科學研究發展的典型范例。
蛋白質結構解析范例
蛋白質作為生物體內關鍵功能的執行者,其結構直接影響運輸、催化、結合和免疫功能等重要的生物過程。雖然測序技術可以揭示蛋白質所包含的氨基酸序列,但任何一個已知氨基酸序列的蛋白質鏈有可能折疊成天文數字中的任何一種可能構象,這使得準確解析蛋白質結構成為長期以來的挑戰。利用傳統技術如核磁共振、X射線晶體分析、冷凍電子顯微鏡等解析已知序列的蛋白質結構方法,需要數年時間才能描繪出單個蛋白質的形狀,昂貴耗時且不能保證成功解析其結構。因此,捕獲蛋白質折疊的底層規律從而實現對蛋白質結構的精準預測,一直是結構生物學領域最重要的挑戰之一。
AlphaFold 2利用基于注意力機制的深度學習算法,對大量蛋白質序列和結構數據進行訓練,并結合物理學、化學和生物學的先驗知識,構建了包含特征提取、編碼、解碼模塊的蛋白質結構解析模型。在2020年國際蛋白質結構預測競賽(CASP14)中,AlphaFold 2取得了矚目的成績,其蛋白質三維結構預測準確性甚至可與實驗解析的結果相媲美。這一突破為生命科學領域帶來了全新的視角和前所未有的機遇,主要體現在3點。
對藥物發現領域產生了直接影響。大多數藥物通過與體內蛋白質特殊結構域的結合而引發蛋白質功能的變化,AlphaFold 2能夠快速計算出海量目標蛋白質的結構,從而有針對性地設計藥物以有效地與這些蛋白質結合。
對蛋白質的理性設計提供了新的可能性。一旦AI對蛋白質折疊的底層規律有了深刻理解,就可以利用這一知識設計出折疊成所需結構的蛋白質序列。這使得生物學家可以根據需求自由設計和改造蛋白質或酶的結構,如設計更高活性的基因編輯酶,甚至是自然界中不存在的蛋白質結構。同時也推動了人們對基因編碼信息在蛋白質層面結構投射規律的理解,并將大幅提高人類對生命的改造能力。
AlphaFold 2徹底改變蛋白質結構解析領域的研究范式。從只能通過費時費力的傳統實驗技術解析蛋白質結構轉變為低門檻、高精度、高通量地預測蛋白質三維結構的新范式,證明通過將蛋白質知識和AI技術相結合,可以提取和學習到高維、復雜的知識,促進對蛋白質物理結構和功能的更深入理解。
基因調控規律解析范例
人類基因組計劃被譽為20世紀人類三大科學計劃之一,揭開了生命奧秘的序幕。盡管編碼生命個體的遺傳信息存儲在DNA序列中,但每個細胞的命運和表型卻因其獨特的時空背景而千差萬別。這種復雜的生命過程由精細的基因表達調控系統所控制,而探索生命普遍存在的基因調控機制是繼人類基因組計劃之后最為重要的生命科學問題之一。不同細胞的基因表達譜是理解生物系統內基因調控活動的理想窗口。然而,僅通過生物學實驗全面解讀基因調控機制,需要捕獲不同生物個體的不同細胞類型在不同環境背景下的對照試驗來觀察。傳統生物信息分析方法只能處理少量數據,對大規模、高維度且缺乏準確標注的生物組大數據難以捕捉數據中復雜的非線性關系。
近年來,自然語言處理技術的不斷突破,特別是大語言模型的迅猛發展,能夠通過訓練語料數據使模型具有理解人類語言描述知識的能力,為解決這一領域問題帶來了新思路。國際多個研究團隊借鑒大語言模型的訓練思路,相繼基于數以千萬計的人類單細胞轉錄組譜數據和龐大的算力資源,利用Transformer等先進算法和多種生物學知識,構建了多個具有理解基因動態關系能力的生命基礎大模型,如GeneCompass、scGPT、Geneformer和scFoundation等。這些生命基礎大模型以基因表達等底層生命活動信息為訓練基礎,利用機器來學習理解這些“低維”的生命科學數據與復雜“高維”的基因表達調控網絡、細胞命運轉變等底層生命機制之間的關聯性和對應規律,實現以低維數據對高維信息的有效模擬和預測。這種對基因表達調控網絡的模擬可以在廣泛的下游任務中表現出卓越性能,為深入理解基因調控規律提供了全新的途徑。
現有的AI驅動生命科學研究的成功案例向我們證明,面對更深入、更系統的生命科學問題,AI有望突破傳統研究方法難以解決的困境、構建從基礎生物層次到整個生命系統的投射理論體系,并進一步推動生命科學向更高階段發展,開啟生命科學研究的新范式。
生命科學研究新范式的內涵和關鍵要素
隨著生物技術的不斷進步、生命科學數據的快速增長、AI技術的飛速發展及其與生命領域的深度交叉融合,AI展示出了對生命科學知識的深入理解和泛化能力,不僅提高了生命科學的研究高度和廣度,也促使生命科學研究由實驗科學為主的第一范式,跨越進入AI驅動的生命科學研究新范式(第五范式,以下簡稱“新范式”)。
通過深入剖析AI驅動生命科學研究的典型范例,筆者認為,生命科學研究的新范式正如一臺智能化的新能源汽車,對標新能源汽車的電池系統、電控系統、電機系統、輔助駕駛系統、底盤系統等核心技術,新范式應具備生命科學大數據、智能算法模型、算力平臺、專家先驗知識和交叉研究團隊五大關鍵要素(圖2)。猶如電池系統為車輛提供能量,生命科學大數據為科學研究提供基礎資源;算法模型則像智能電控系統,賦能深入理解生物系統的運行機制;算力平臺可比喻為電機系統,負責處理海量的科學數據和復雜的計算任務;專家先驗知識則像輔助駕駛系統,為科學家提供方向引領和實施經驗;交叉研究團隊類似于底盤系統,負責整合不同領域的知識和技能,通過跨學科合作提高研究效率,推動生命科學的發展。

關鍵要素一:生命科學大數據
生命科學大數據是新范式“汽車”的“電池”系統。隨著新型生物技術的發展,具有多模態、多維度、分布分散、關聯隱匿、多層次交匯等特點的生命科學大數據逐漸形成;只有對生命科學大數據進行有效整合并利用創新AI技術充分挖掘數據,才能夠打破人類科學家的認知局限、促進新發現的產生并拓展生命科學的探索范圍。例如醫療視覺大模型,通過整合多來源、多模態、多任務的醫療圖像數據,實現了在少樣本和零樣本條件下的多種應用;跨物種生命基礎大模型GeneCompass,通過有效整合全球開源的單細胞數據,在超過1.2億個單細胞的訓練數據集上實現了對基因表達調控規律的全景式學習理解等多個生命科學問題的分析。
關鍵要素二:智能算法模型
智能算法模型是新范式“汽車”的“電控”系統。從浩如煙海的生命科學大數據中涌現生命的新規律和新知識,需要創新AI算法和模型;如何研發利用生命科學適配的AI算法、提取有效的生物特征、構建大規模生物過程動態模型,是當前新范式的中心問題。例如,Gerstein團隊使用貝葉斯網絡算法預測蛋白質相互作用的成果發表于Science,為經典機器學習在生物信息領域發展奠定了基礎;圖卷積神經網絡算法被用于分析蛋白質—蛋白質相互作用網絡和基因調控網絡等生物分子網絡,拓展了生命科學領域的研究方向;AlphaFold 2使用Transformer模型,能夠在高準確度的基礎上快速計算出大量蛋白質的結構,都展示出了AI算法模型在生命科學研究新范式中的重要性。
關鍵要素三:算力平臺
算力平臺是新范式“汽車”的“電機”系統。算力是實現AI運行的基礎,深度學習、大模型技術等適用于生命科學研究新范式的AI算法模型的不斷發展,使AI模型訓練需要更強大、更高效的算力平臺支持。面向新范式,未來應構建能夠支撐AI賦能生命科學研究的硬件能力平臺,包括建設高速大容量存儲系統、構建高性能高吞吐量超級計算機、研發專門用于處理生命科學數據的芯片、設計用于加速生物模型推理和訓練的專用處理器等,為生命科學研究提供高效、可靠的計算和處理能力,以應對生命科學領域產生的海量數據、滿足生命科學領域復雜模型構建的計算需求,保障AI在生命科學領域的應用和創新。
關鍵要素四:專家先驗知識
專家先驗知識是新范式“汽車”的“輔助駕駛”系統。新范式下,已有的生命科學知識將為AI算法模型提供寶貴的訓練約束條件、重要的背景和特征關系,幫助解釋和理解生命科學數據的復雜性、驗證和優化AI在生命科學領域的應用;能夠在AI算法設計和模型構建時發揮重要的指導作用,促進更加準確、高效地解決生命科學問題,推動生命科學研究向更深入、全面的方向發展。例如,通過嵌入生命科學專家先驗知識和人類注釋信息編碼,新型基因表達預訓練大模型提高了對生物數據間復雜特征關聯關系的解釋,展示出更為優異的模型表現。
關鍵要素五:交叉研究團隊
交叉研究團隊是新范式“汽車”的“底盤”系統。新范式下,一支由AI專家、數據科學家、生物學家和醫學家等組成的多學科交叉研究團隊對于實現跨越式的生命科學發現至關重要。多元背景緊密協作的交叉研究團隊能夠整合AI、生物學、醫學等領域的專業知識,提供多元化的視角和方法,為全面理解和解決生命科學中的復雜機制問題提供牢固基礎,為創新性解決方案提供更多可能性,從而推動生命科學領域的突破性發現和進展。
新范式賦能的生命科學研究前沿及我國面臨的挑戰
傳統的研究范式對生命的探索如同管中窺豹,生物學家在生命科學的不同細分領域各自奮戰。隨著新范式的不斷發展,生命科學研究將迎來以AI預測、指導、提出假說、驗證假設為特點的新型研究模態,迸發出一批快速發展的生命科學新范式前沿研究方向,并展現出新范式變革帶來的發展增益。然而,在當前條件下加速推進我國生命科學研究新范式的建立和推廣,仍面臨一系列巨大的挑戰。
新范式賦能的生命科學研究前沿
結構生物學。目前在結構生物學領域,以AlphaFold為代表的AI應用技術仍停留在“從序列到結構”的蛋白質結構預測和設計階段,還無法實現復雜生理條件下蛋白質結構和功能的模擬與預測。更高質量、更大規模的蛋白質數據和新型算法的出現,將有望對不同生理狀態和時空條件下的生物大分子結構和功能進行系統解析,并實現蛋白質“從序列到功能”甚至“從序列到多尺度相互作用”的智能化結構解析與精細設計。
系統生物學。當前的組學數據分析仍局限于較低維度的生物組學觀測水平,還未形成從基因水平到細胞水平甚至生物個體乃至群體組學水平的全維度觀測。新范式將融通多維度、多模態的生物大數據和專家先驗知識,提取生物表型的關鍵特征,構建多尺度生物過程解析模型,還原復雜生物系統運行的底層規律,形成基礎而廣泛適用的系統生物學研究新體系。
遺傳學。隨著多組學數據的積累和新型基因大模型的出現,遺傳學研究已進入新范式推動的快速發展階段,基于基因表達譜數據的自監督預訓練大模型有望成為解析基因調控規律、預測疾病靶點的有力工具,拓展遺傳學研究的探索邊界。
藥物設計開發。隨著AlphaFold的出現和一批分子動力學模型的發展,AI模型已經被用于預測和篩選藥物候選分子。未來新范式將進一步推動該領域的發展,有望出現AI輔助的全流程藥物設計開發體系,能夠自主完成藥物結構和性質的優化設計、實現候選藥物的有效性和安全性模擬預測、生成藥物的高效合成和生產工藝方案,極大加速藥物的開發和生產過程。
精準醫學。計算機視覺、自然語言處理和機器學習等AI技術已廣泛滲透到生物影像、醫學影像、疾病智能分析及靶點預測等精準醫學子領域。例如,基于AI的診斷系統在準確度上已經可以媲美甚至在某些方面超過資深的臨床醫生。然而,現有的模型大多受制于數據的偏好性,存在魯棒性差、通用性低等問題,隨著新范式驅動的通用精準醫學模型的出現,將有助于更加快速準確地診斷疾病、解析疾病的分子機制、發現新的治療靶點,提高人類的健康水平。
我國生命科學研究新范式面臨的挑戰
面對生命科學研究新范式發展的新形勢、新要求,我國仍面臨高質量生命科學數據資源體系缺乏、AI關鍵技術與基礎設施不足、新范式下的交叉創新科研新生態匱乏等方面的巨大挑戰。
高質量生命科學數據資源體系缺乏
盡管我國在生命領域的科研投入持續增加,但在一些前沿領域,我國科學家仍依賴國外高質量數據,而國內數據的建設和使用相對滯后,我國生命科學數據資源還存在分布不均衡問題,需要更好地統籌協調和資源整合,實現高質量生命科學數據資源的高效匯聚和系統化提升。此外,在生命科學數據的收集、傳輸和存儲過程中,數據安全問題亟待加強,特別是生物數據的隱私和安全問題仍需要引起重視。
面對這些挑戰,我國需要加強科學數據資源的整合與共享,推動生命科學數據資源的可持續發展,提高數據的質量和安全性,加強數據管理與供給模式的變革,推動跨領域多模態科技資源融合服務能力的提升,以滿足新范式下科研需求的發展。
AI關鍵技術與基礎設施不足
我國AI驅動新科研范式的核心技術相對匱乏,自主原創的算法、模型、工具仍待大力發展。針對生命科學大數據的海量、高維、稀疏分布等特征,亟需發展復雜數據的先進計算與分析方法。未來應開發更加適合生命科學應用的硬件、軟件和新計算介質,并在生命科學和計算科學的融合過程中,探索新的計算-生物交互模式。簡而言之,新范式研究對數據、網絡、算力等資源的綜合能力提出了新的要求,需要加快推進新一代信息基礎設施建設,解決算力“卡脖子”問題。
新范式下的交叉創新科研新生態匱乏
現有AI驅動的生命科學研究方式大多為課題組自發組合的“小作坊”模式,缺乏新范式發展所需的交叉創新環境。美國在2023年發布的《國家人工智能研發戰略計劃》更新版本中也著重強調了人工智能研究的跨學科交叉發展的重要性。因此,新范式下的科研生態應鼓勵更為廣泛的多學科“大交叉”“大融合”,建立干濕結合、理實交融的新型研究模式,持續培養高水平復合型交叉研究人才。
在新形勢下我國也已經開始廣泛布局和推進交叉學科的發展。《中華人民共和國國民經濟和社會發展第十四個五年規劃和2035年遠景目標綱要》中指出要推動互聯網、大數據、人工智能等同各產業的深度融合。結合我國生命科學領域的實際發展情況,我國生命科學領域發展更應著眼于將AI賦能生命科學研究的范式變革融入我國新時代的國家發展遠景布局中,實現以點帶面的整體效應建立更加開放的新型科研生態和發展環境。
近年來,生命科學領域正經歷著前所未有的巨變,這一領域的發展不僅受到生物技術和信息技術的雙重推動,更受到AI技術進步的巨大影響。這一變革的核心在于從傳統的主要依賴于人經驗的假說和實驗驅動的科研范式向大數據和AI驅動的新研究范式的演變。這意味著我們不再僅僅依賴于實驗和假說,而是通過大數據分析和AI技術主動揭示生命的奧秘。更廣泛的,這個演變將廣泛改變或促進不同層面的科學研究活動的變革,涵蓋了認識論、方法論、研究組織形式、經濟社會及倫理法律等眾多層面。
綜合而言,我們正身臨著一個充滿變革和希望的時代,生命科學的革新與科技的進步共同繪制出人類對生命奧秘更深層次探索的未來藍圖。可以預見,隨著通用AI的進一步發展,生命科學研究將在不遠的未來實現干濕融合、人機協同的新模式,迎來AI自驅抽象新知識、新規律的“預人所未見,思人所未思”的科學新時代。
(作者:李鑫,中國科學院動物研究所 北京干細胞與再生醫學研究院;于漢超,中國科學院前沿科學與教育局;編審:金婷;《中國科學院院刊》供稿)





